This week at IJCAI 2021, Michael Katz, Tim Klinger, George Konidaris, Matt Riemer, Gerry Tesauro, and I are presenting a paper about making black-box planning more efficient through the discovery and use of macro-actions that intentionally modify a small number of state variables. We describe how to find such “focused macros”, and show that they have very intuitive explanations and end up being useful for a wide variety of deterministic planning problems.
[Paper] [Code] [Talk] [Poster] [Bibtex]
AI Planning
AI planning is a way to formalize the abstract problem of making a sequence of decisions to achieve some desired goal.

For example, suppose we want to tackle the planning problem of solving the Rubik’s cube. If you’re not familiar with the Rubik’s cube, it’s a cube-shaped plastic puzzle with square, colored stickers. The puzzle twists, and this allows the stickers to change positions. Typically the puzzle starts in some randomly scrambled state, and the objective is to twist the faces so that all the stickers on each side share the same color.
It’s often helpful to visualize a given planning problem as a search tree:
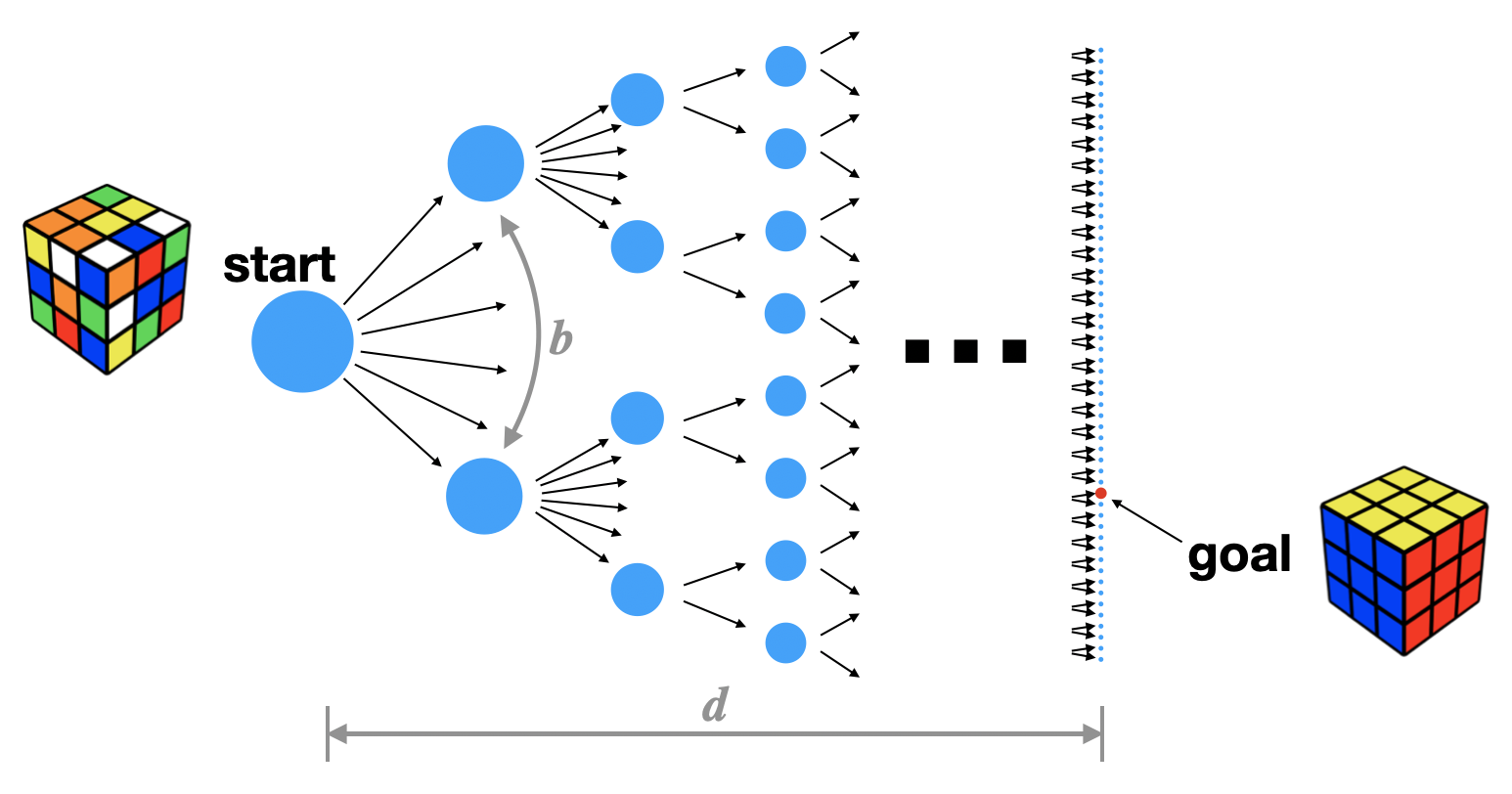
Each of the blue nodes represents a particular state of the cube. Each of the arrows represents a particular action that the planning agent can take, such as rotating the left face clockwise, or the top face counter-clockwise. The cost of planning is exponential in the depth \(d\) of the search tree: \(O(b^d)\), where \(b\), the branching factor, is the number of actions available at each state.
For Rubik’s cube, there are 12 actions if we restrict ourselves to using quarter-turns, and the problem depth is 26, which means the search tree contains approximately \(12^{26}\) nodes, or roughly 30 billion times as many nodes as the number of seconds since the Big Bang. It’s an extremely large search tree.
Fortunately, planning strategies like heuristic search can help us avoid large sections of the search tree and thereby guide the search towards the most promising areas.
Heuristic Search
In the context of planning, a heuristic is a function that estimates the number of steps to reach the goal from a given state. Heuristics enable “best-first search”, which prioritizes investigating nodes with the lowest heuristic value first.
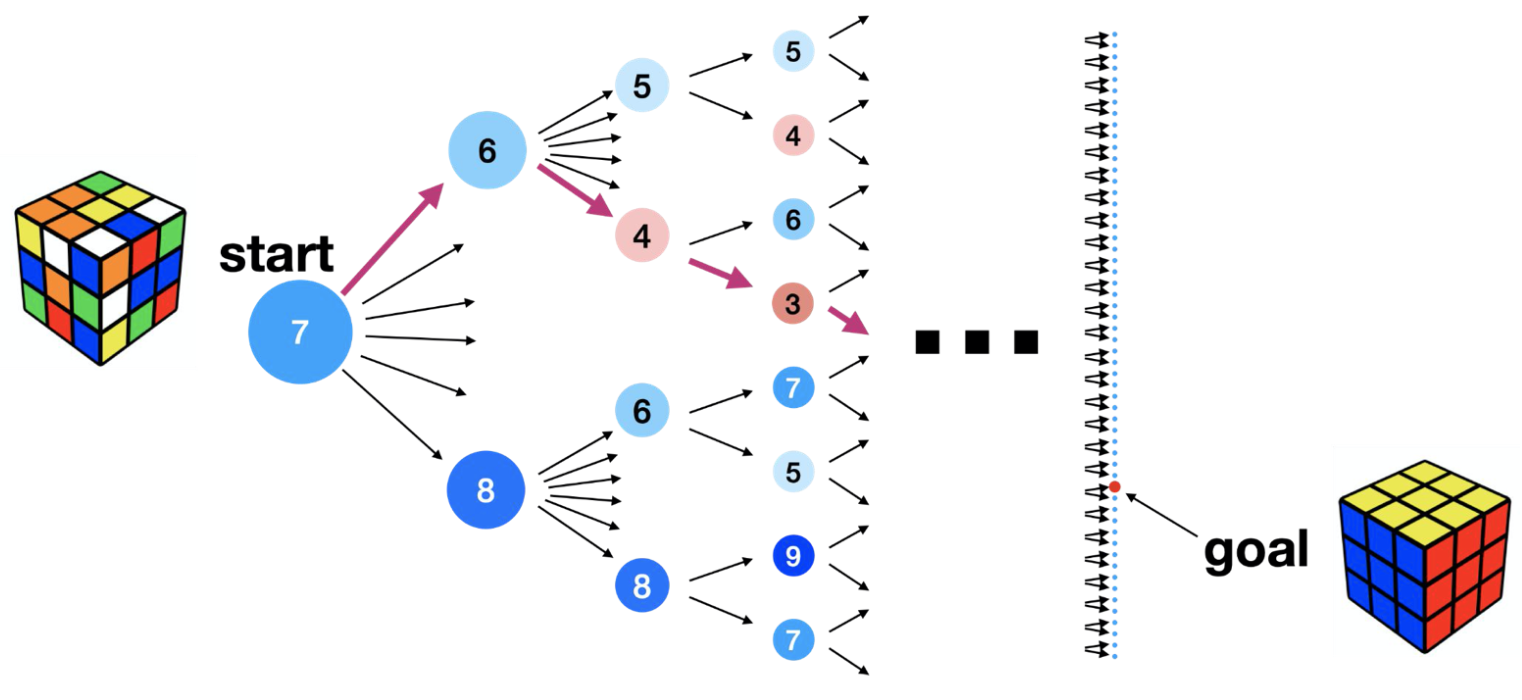
It’s important to remember that the heuristic generally isn’t perfect. It can overestimate or underestimate the true cost (i.e. number of steps) to the goal. But as long as it’s roughly correlated with the true cost, it will still help guide our search. If at some point our search reaches a state that seems like a dead end, we can always backtrack and continue with the next-best node in the tree.
Classical Planning vs. Black-Box Planning
There are a number of different AI planning frameworks that make different assumptions about the information that is available to a planning agent.
In some planning frameworks, like classical planning, the agent has a detailed model of how each of the actions works, and it can exploit that description during planning for improved efficiency. Each action model consists of a precondition, describing when the action can run, and an effect, describing what it does. Action models provide lots of useful information to exploit when designing a heuristic. For example, we can analyze which actions modify which state variables and imagine hypothetical actions that have less restrictive preconditions or that can only make forward progress towards the goal. All of these can lead to useful, informative search heuristics.
By contrast, in black-box planning, we don’t have an explicit action model. Instead we just have a simulator that we can query whenever we want to know whether a particular action can run in a given state, or what happens if it does. In black-box planning, essentially all we can do is ask the simulator to reveal more of the search tree to us, one arrow or node at a time. That means black-box planning is in some sense a more general framework than classical planning, but it also means most of the classical planning techniques for designing heuristics don’t apply, and we’re limited to using very simple heuristics.
The Goal-Count Heuristic
Playing with Rubik’s cube for the first time without any explanation of how it works is a lot like black-box planning. You have no idea what you’re doing—all you can do is try some actions and see what happens. But even if solving the puzzle is beyond your current abilities, you can still rather quickly start to build up an intuitive sense of whether you’re making progress.
To demonstrate this intuition, consider trying to arrange the cubes below from least solved to most solved (left to right):

[Reveal answer…]
More than one answer exists depending on how you want to measure progress, but one reasonable answer is: D, C, A, E, B. In particular, any answer ought to put D on the left, since it’s the only state with a fully scrambled bottom layer, and put B on the right, since that’s the only state where the cube is fully solved.
Humans typically use a very intuitive heuristic, called the goal-count heuristic, to measure Rubik’s cube progress. The key idea is simply to count the number state variables that still need to be modified in order to satisfy the goal condition. This is a very simple heuristic, it’s very easy to compute, and it also happens to be compatible with black-box planning. All it requires is a known goal condition and state variables to count.
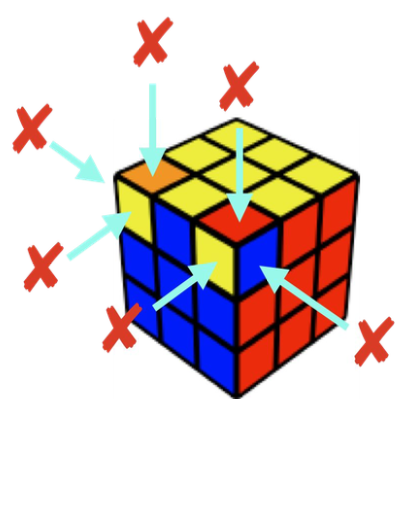
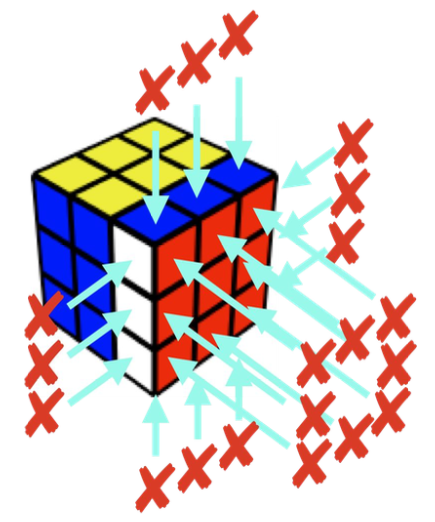
For the Rubik’s cube, this amounts to something like counting the number of stickers that are out of place.
 |
 |
|
| Heuristic = 6 | Heuristic = 20 |
For the two cube states above, counting the number of out-of-place stickers gives 6 and 20 respectively. (Note that even though the red stickers all match on the right cube, technically they’re still out of place, since they are connected to the adjacent out-of-place stickers.)
Now you might be thinking to yourself, “Wait a minute! If we just do a counter-clockwise turn of the red face, we can solve the cube on the right in a single step!”
That’s true, and 1 step is a lot fewer than the 20-step heuristic estimate. And if you really know your stuff, you might also point out that the fastest way to solve the cube on the left takes 14 steps, not 6. That means this heuristic is pretty bad: it’s not even remotely correlated with the true cost to reach the goal. And actually, the goal-count heuristic can be rather uninformative for other planning problems besides Rubik’s cube as well.
Because of this discrepancy between the heuristic and the true planning cost, if we just forge ahead and try to do best-first search, we won’t be able to actually solve the problem.
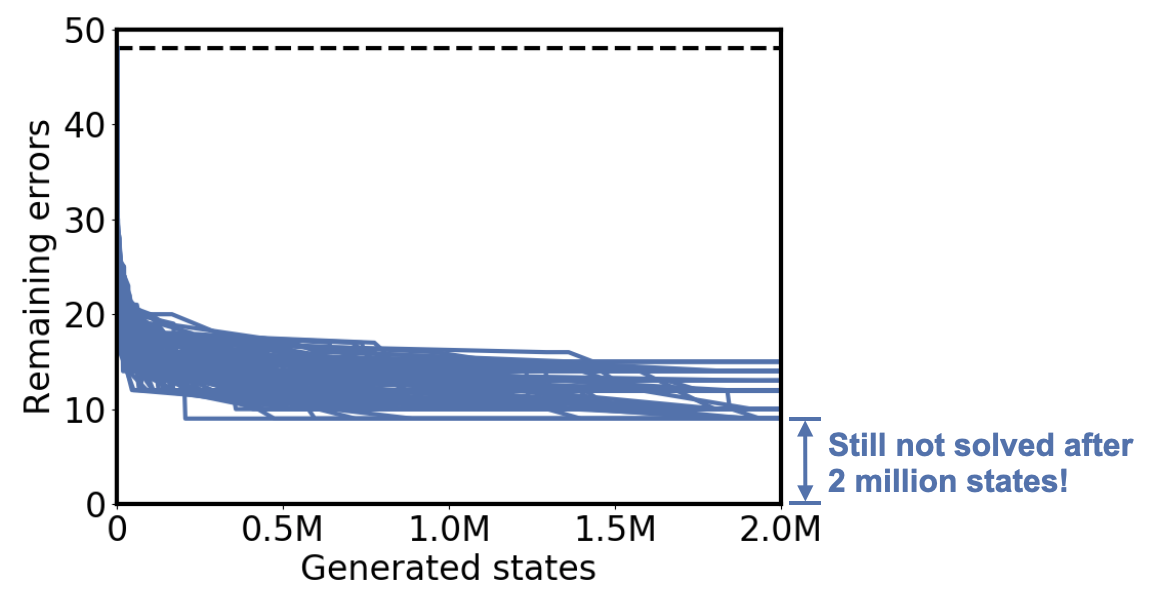
Here’s a graph of the number of errors remaining—that is, the number of stickers that are still out of place—versus the number of states in the search tree we’ve looked at so far.
Notice that the number of errors is going down over time, but it never reaches zero. That means in these 100 attempts, we never solved the cube once, even though we looked at 2 million states!
So we might ask ourselves: if performance is this bad, does the heuristic actually help us at all?
It turns out that the answer is “yes”, provided that we can learn useful macro-actions.
Macro-Actions
A macro-action is a pre-defined sequence of actions. If we go back to our search tree from before, you can think of macro-actions as directly connecting two states that would have otherwise been several steps away.
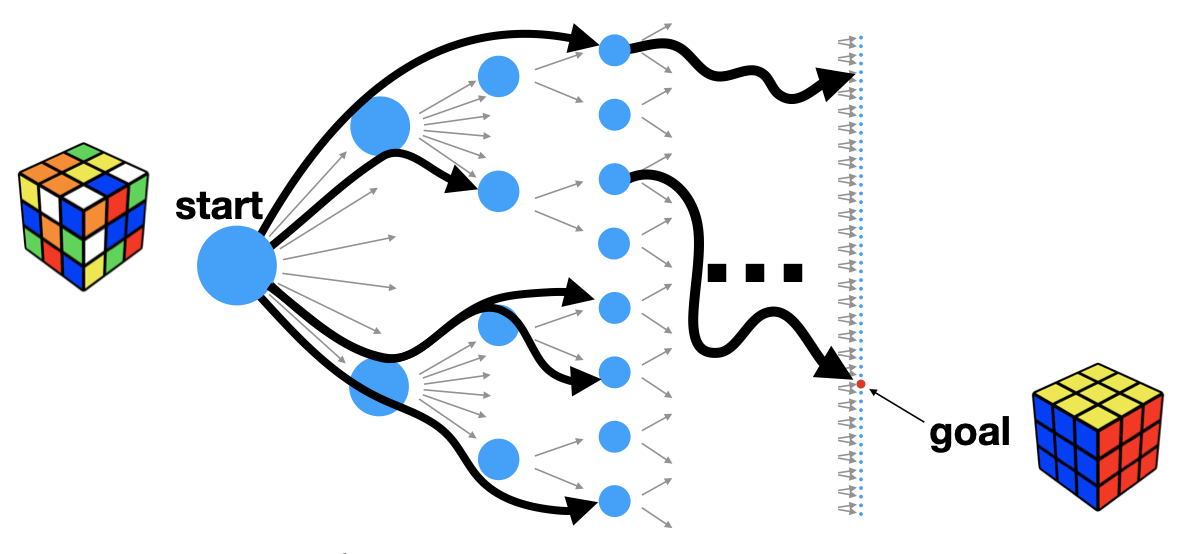
Before, we might have had to turn the left face clockwise, top face clockwise, and then the left face counter-clockwise again. Now we have an action sequence that gets us to the resulting state in a single step.
Macro-actions are nice because they decrease the depth of the search tree, i.e. we don’t need as many steps to reach the goal. The downside is that we still have the original “primitive” actions, so adding macros increases the branching factor. If we’re not careful about which macro-actions we add, we could wind up trying to navigate an even more complicated search tree than before!
To decide which macros are worth considering, we’ll take inspiration from human experts.
Expert Macro-Actions
One place where macro-actions are remarkably effective is in Rubik’s cube “speedsolving” competitions. The way the competitions work is that there’s a timer that starts when you pick up the scrambled cube. Then you try and solve the cube as fast as possible, and when you’re done, you place it back on the table, and the timer stops. The world record for speedsolving is currently just under three and a half seconds.
 Feliks Zemdegs, an Australian speedcuber at the Swisscubing Cup Final, 2018. [Source]
Feliks Zemdegs, an Australian speedcuber at the Swisscubing Cup Final, 2018. [Source]
{kind=link}
If you’ve ever spent time with a Rubik’s cube, you’ll realize that three and a half seconds is ridiculously fast. There’s no time to evaluate a really complicated heuristic—there’s barely any time to think at all. This is why the goal-count heuristic is so useful. You just visually estimate how many stickers are out of place and hope for the best.
But these human experts have another trick: before the competition, they memorize and practice dozens of macro-actions (called “algorithms” in the speedsolving community) that accomplish various useful operations on the cube.
Here are a few examples:
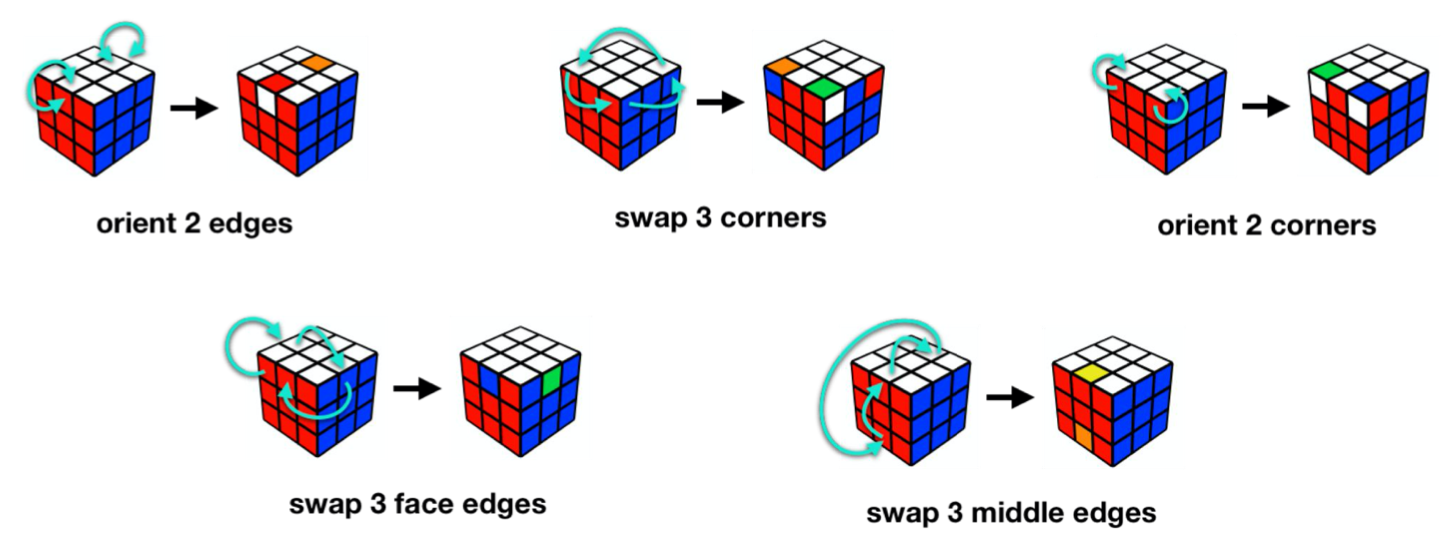
During your speedsolving run, if you get into a state that requires swapping three corners, hopefully you’ve already memorized a macro-action to swap three corners, and then you can simply execute the pre-learned macro to get to the desired next state.
Notice that the expert macros above typically do one thing and one thing only. These macros might modify other pieces in the process (and in fact they do), but they always put things back how they were by the time they’re done. Ultimately, only the stickers the macro-action is supposed to change are affected.
And these expert macros are very effective when we add them to our best-first search:
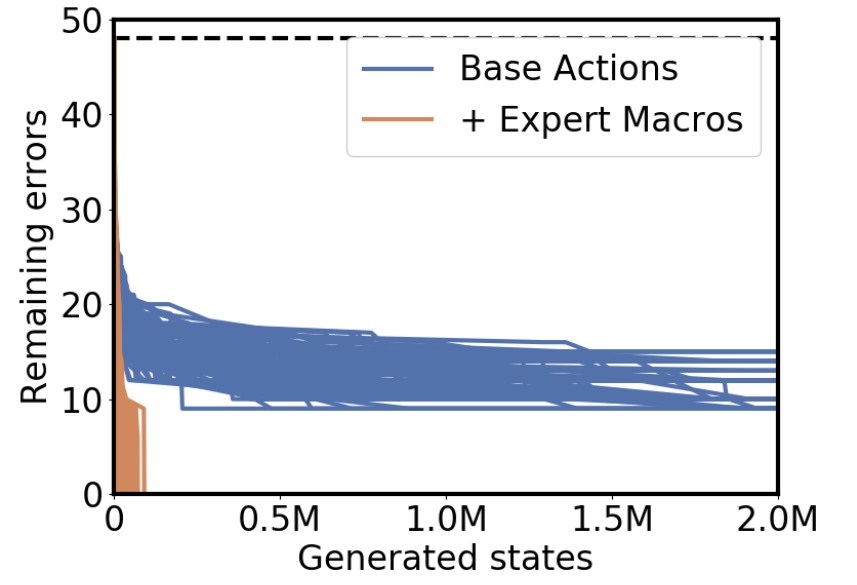
We’re now able to solve the cube 100% of the time, using less than 5% of the original search budget.
Effective Macros are “Focused”
The reason that expert macros are so effective turns out to be directly related to the fact that they are “focused”—that is, they only modify a few specific state variables (sticker locations) and minimize side effects to others.
Here we compare the expert macros against “random” action sequences as well as the original base actions:
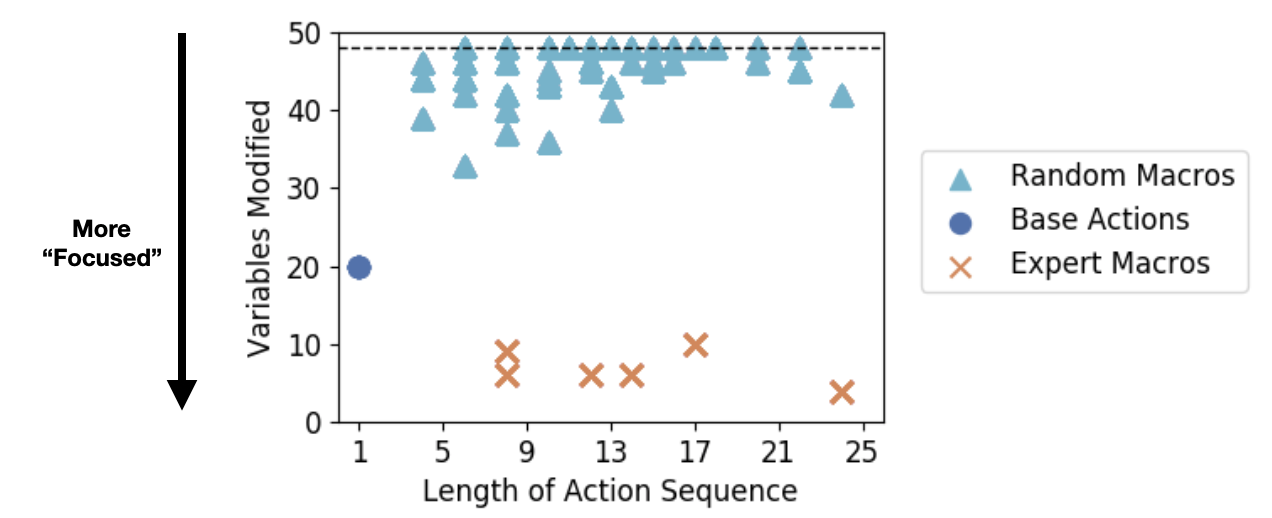
This plot shows the number of stickers each macro-action modifies versus the length of that macro’s action sequence. As a point of reference, the dark blue dot represents the base actions, which take exactly one step and modify 20 sticker locations. Meanwhile, the macro-actions all take several steps, with random macros modifying many stickers and expert macros modifying only a few.
Maybe it’s unsurprising then, that random macros perform worse than planning with just the base actions:
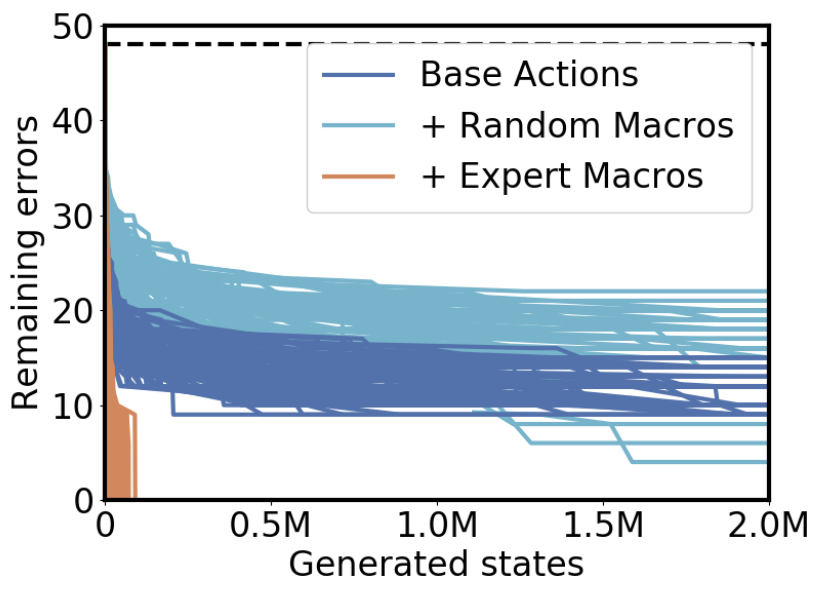
Clearly macros that are more focused tend to be better for planning with the goal-count heuristic. But it would be a shame if we had to hand-specify expert-macros for every planning problem; ideally we’d like to have the planning agent learn macros for itself.
So the key question that remains is: how can we automatically discover focused macros?
Discovering Focused Macros
To discover focused macro-actions, we’ll return to our search tree from before. We’ll start with an arbitrary initial planning state, but this time we’ll ignore the goal information and just consider some macros:
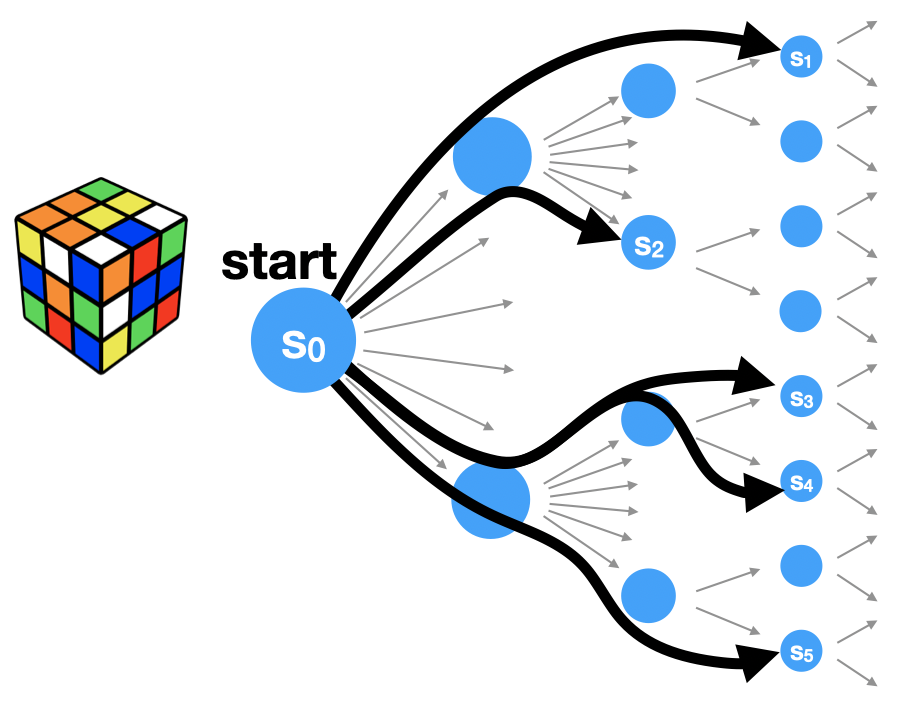
For each candidate macro, we’re going to measure it’s “effect size”, which is just the number of state variables that change from the start state to the end state of the macro. We’re going to ignore any changes that happen along the way—we’re just looking at the initial state and the final state, and computing how many state variables change between \(s_0\) and (for example) \(s_1\).
Suppose we measure the effect size for a few candidate macros:
| Macro-Action | Initial State | Final State | Effect Size | |||
|---|---|---|---|---|---|---|
| \(m_1\) | \(s_0\) | \(s_1\) | 14 | |||
| \(m_2\) | \(s_0\) | \(s_2\) | 8 | |||
| \(m_3\) | \(s_0\) | \(s_3\) | 10 | |||
| \(\cdots\) | \(\cdots\) | \(\cdots\) | \(\cdots\) |
In this case, we’d say that macro \(m_2\), which goes from \(s_0\) to \(s_2\), is the most focused, since it modifies the fewest state variables.
This allows us to discover macro-actions using best-first search, expanding nodes with the lowest effect size first. Earlier, we used best-first search for planning, guided by the goal-count heuristic, but here we’re using it for macro learning, guided by this lowest effect size heuristic.
We’ll store the \(N\) best macros in a library (ignoring trivial macros that don’t modify any state variables), and later when it comes time to do planning, we’ll augment the base actions with these learned, focused macro-actions.
Results
Before we use the focused macros for planning, let’s visualize what they look like when compared to the base actions and the other macro types:
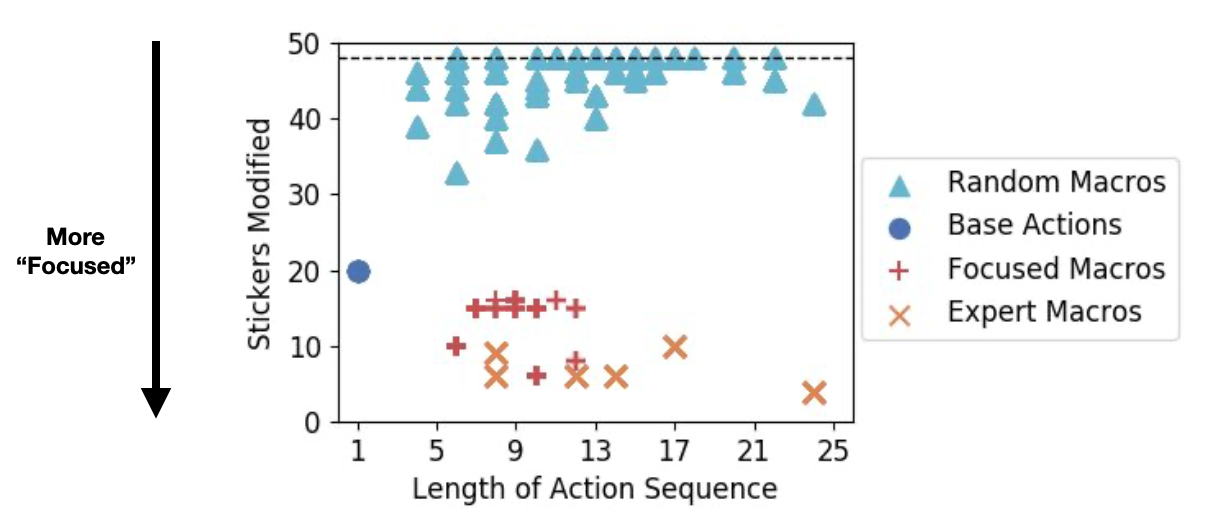
Right away, we can see that the focused macros (marked with a red +) are quite similar to the expert macros: they modify very few stickers.
And if we take a look at what the learned macros are doing, we find that they have very intuitive explanations as well. Here’s an example (corresponding to the red + in the top right) that takes 12 steps and modifies 15 state variables:
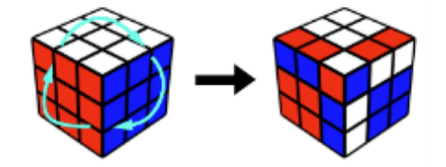
This learned macro swaps three edge-and-corner pairs, and is very similar to the kind of macro you could imagine human experts using in a speedsolving competition.
What’s even more encouraging though, is that these focused macros are beneficial for planning:
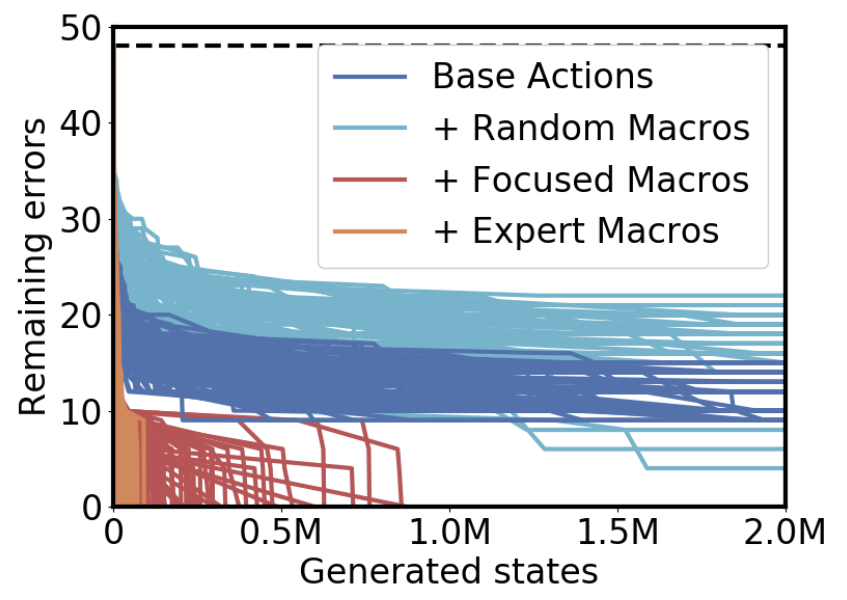
Focused macros, in red, are able to solve the cube quickly and reliably. Notice that most of the red lines are very close to the orange “expert macro” lines. That means we were able to solve most of the puzzles in only slightly less time than it would have taken if we’d had the expert macros available to us.
And that makes sense! Earlier we talked about how adding macro-actions to the search tree decreases the depth but also increases the branching factor. The focused and expert macros essentially only add “helpful” branches to the search tree, because they make the goal-count heuristic more accurate. By contrast, the random macros add “unhelpful” branches, and that makes the search even slower than if we just used the base actions.
Accounting for the Macro-Learning Budget
One nice property of our approach is that the focused macro-actions only need to be learned once, for the first puzzle, and we can then reuse them for any additional puzzles we want to solve. Here we solve 100 puzzles, which means the time it takes to learn the focused macros can essentially be divided by 100.
But even if we account for the entire macro-learning budget as additional search time, we are able to learn useful macros in just 1 million steps, which leaves us with plenty of planning budget to spare:
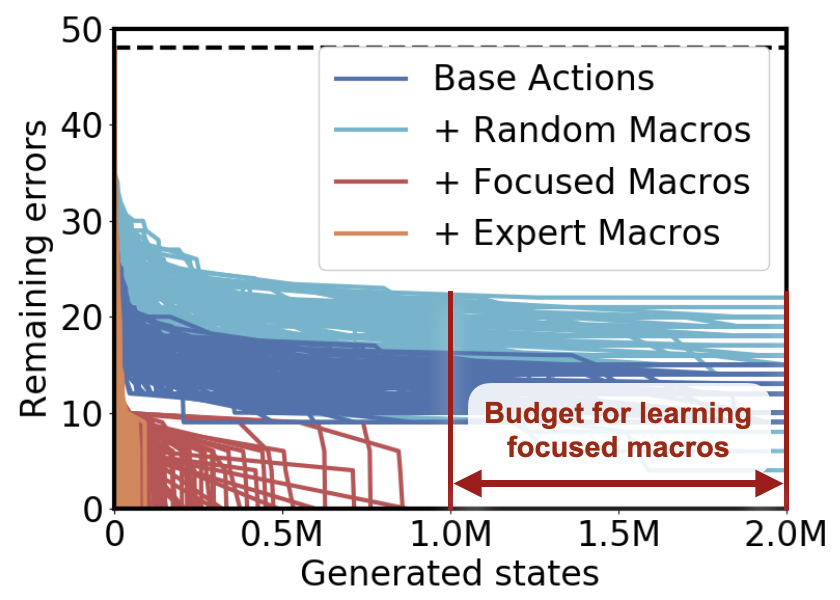
That means that the entire process—of automatically discovering focused macros and then using them to plan—still happens fast enough that we can solve all 100 puzzles within the original search budget. Remember, with the base actions alone, we couldn’t solve any puzzles!
Wrapping Up
At the beginning of this post, we discussed how the cost of planning is exponential in the depth of the search tree, and saw that we could use heuristics to guide our search towards more promising directions.
Since we were mainly interested in black-box planning, we couldn’t take advantage of explicit action models to derive accurate heuristics. Instead, we had to rely on the goal-count heuristic, which we saw is often very uninformative.
However, by drawing inspiration from human experts, we were able to spend some of our search budget to look for useful, focused macro-actions, and found that these learned macros not only looked remarkably similar to the expert macros, but they also dramatically improved the speed and reliability of black-box planning.
In the full paper, we show that this approach is useful for solving a wide variety of planning problems beyond Rubik’s cube. We also show that it’s compatible with more advanced black-box planning heuristics. Finally, we show that because the goal information isn’t required for learning the macros, we can actually learn macros for one goal, and then subsequently use them to solve problems with other goals. Check out the full paper to learn more!