This post contains notes from my recent attempt to understand group theory and how it relates to learning disentangled representations.
It assumes you have no knowledge at all about group theory, because when I started writing it, neither did I.
- Prologue: The disentangled representation learning problem
- Part 1: Group Theory
Prologue: The disentangled representation learning problem
A few weeks ago, I was reading this recent paper out of Deepmind, which proposed a mathematical definition of “disentangled representations” – something I’ve been wishing existed for some time.
Representation learning is the process of constructing an abstraction that is suitable for describing a particular problem, such that the important information for solving the problem is preserved, and the rest of the information is thrown away.
For example, suppose the problem is that of playing chess. A player needs to be able to decide which move to play next, and the only information that is actually important for doing so is the configuration of the pieces on the board, and the rules of the game. The physical design and orientation of the board and the pieces are irrelevant. The lighting conditions, temperature, and noise level in the room are irrelevant. The previously played move is also irrelevant, since it no longer has any additional effect on the outcome of the game. A “good” representation throws all of this irrelevant information away, and keeps only what matters: the positions of the pieces and the rules governing how they can move about the board.
But good representations do more than this. They make the important information about the problem accessible; they make it easy to use; and often they make it easy to interpret, as well. Many problems, including chess, have some underlying structure that can be decomposed into distinct, non-interacting parts. In chess, only one piece can move at a time, so it is natural to consider an abstract representation where the position of each piece is represented individually.
A representation that reflects the underlying structure of the problem is called a disentangled representation. It decomposes the distinct aspects of the problem into separate, non-interacting parts, and captures each part individually in the representation.
But while the above description of disentanglement might make some intuitive sense, it lacks a rigorous mathematical definition. The authors of the Deepmind paper sought to remedy this situation by developing a new definition using tools from abstract algebra and group theory.
To their credit, Higgins, Amos, et al. did an excellent job of articulating the core of their idea in an approachable way, despite the fact that it involves some pretty abstract math concepts. The vast majority of people would never have seen any of this stuff (let alone understood it), unless they had spent a good amount of time inside either a math department, a math textbook, or both. Unfortunately it’s been years since I’ve spent any quality time in either one, so as I was reading the paper, I felt like the most important parts were going over my head.
And yet somehow, even without fully grasping the details, I still felt like there was something fascinating and important about this paper – something that I needed to understand.
The rest of this article is my attempt to do that.
Part 1: Group Theory
Definition of a group
A group is two things. It’s a set \(G\), and a binary operator \(\bullet\), such that the following properties hold:
- Closure: For all \(a, b \in G\), we have \(a \bullet b \in G\).
- Associativity: For all \(a, b, c \in G\), we have \((a \bullet b) \bullet c = a \bullet (b \bullet c)\).
- Identity: There exists an element \(e \in G\) such that, for every element \(a \in G\), we have \(a \bullet e = e \bullet a = a\).
- Inverse: For each \(a \in G\) there exists an element \(a^{-1} \in G\), such that \(a \bullet a^{-1} = a^{-1} \bullet a = e\).
Okay, but that’s just math. What does all that mean?
It’s actually not as bad as it seems. Let’s take each of the properties one at a time.
-
Closure
If you apply the binary operator to any two elements \(g\) and \(h\) from \(G\), then the result is also in \(G\). That is to say: \(g,h \in G \rightarrow (g \bullet h) \in G\).
If \((G, \bullet)\) satisfies the closure property, we say that \(G\) is closed under the operator \(\bullet\). This is a nice property because it means no matter how many times we apply the operator, the result will always be in the set we started with.
-
Example
Consider the set of fruits \(\{apple, banana, pineapple, strawberry\}\), and let \(G\) be the set containing all possible combinations of these fruits (assuming order doesn’t matter): \(G = \{\{apple\},\) \(\{apple, banana\},\) \(\{banana, strawberry\}, ...\}\). Let our operator \(\bullet\) be the set-union operator, which combines all the fruits in one combination with all the fruits in another. Then \((G, \bullet )\) satisfies the closure property, since any union of two combinations from \(G\) must produce another combination in \(G\). There’s no way to create a combination of fruits that isn’t in \(G\) (for example, a combination containing \(mango\)) using just the union operator on combinations of the fruits above.
-
Non-example
Let \(G\) be the set of positive integers, and let our operator \(\bullet\) be the subtraction operator. Then \((G,\bullet)\) violates the closure property, since it’s possible to subtract two positive integers and obtain an integer that is negative.
-
-
Associativity
Since \(\bullet\) is a binary operator, we can only apply it to exactly two elements from \(G\) at a time. Suppose we have a sequence of three elements, \(a\), \(b\), and \(c\), and we want to apply \(\bullet\) repeatedly to pairs of consecutive elements until we have only a single element remaining, i.e. we’d like to obtain \(a \bullet b \bullet c\).
We can actually do this two ways. We can either start with \((a \bullet b)\), or we can start with \((b \bullet c)\). The associativity property says that either way, we’ll get the same result. In other words, for all \(a, b, c \in G, (a \bullet b) \bullet c = a \bullet (b \bullet c)\).
It’s important to realize that associativity is about the order of operations, not the order of the elements. Some operators care about the order of their arguments, like when you’re subtracting two integers. Swapping the order of \(a\) and \(b\) does not necessarily give you the same result: in general, \(a \bullet b \neq b \bullet a\). (If \(a \bullet b = b \bullet a\) for all choices of \(a\) and \(b\), this would be a different property, called commutativity.)
-
Example:
The set of positive integers with the addition operator satisfy the associative property, since the addition operator can be applied to consecutive pairs in any order.
-
Non-example
The set of integers with the subtraction operator violate the associative property, since the order of operations matters: \((7 - 4) - 2 \neq 7 - (4 - 2)\).
-
-
Identity
Suppose we have a long sequence of elements, \(x_1\), \(x_2\), …, \(x_n\), and we want to apply our operator \(\bullet\) repeatedly to pairs of consecutive elements until we have only a single element remaining. We might like to know whether we can save ourselves some work by ignoring portions of the sequence which have no effect on the result.
The identity property states that the set \(G\) contains a special element \(e\) such that if we apply our operator \(\bullet\) to \(e\) along with any element \(a \in G\), the result is just \(a\) again. Formally, there exists an element \(e \in G\), such that for every element \(a \in G\), the equation \(a \bullet e = e \bullet a = a\) holds.
That means anywhere we see \(e\) in our sequence, we can remove it, and anywhere we notice a subsequence \((x_i \bullet x_{i+1} \bullet \ \cdots\ \bullet x_{i+k})\) that is equal to \(e\), we can remove it as well.
-
Example:
The positive integers under multiplication satisfy the identity property, since since the element 1 is a positive integer, and for any positive integer \(a\), we have \(a \bullet 1 = 1 \bullet a = a\).
-
Non-example:
Let \(G\) be the set of all 3-dimensional vectors, and let our operator \(\bullet\) be the cross product. Then \((G,\bullet)\) violates the identity property. For any two vectors \(a, b \in \mathrm{R}^3\), the cross product \(a \times b\) is also a vector in \(\mathrm{R}^3\) (closure). However, for two vectors \(a\) and \(b\), either \(a \times b\) is zero, or it points in a direction that is mutually orthogonal to \(a\) and \(b\). That means there is no element \(e\) such that, for any element \(a\), the cross product \(e \times a = a \times e = a\). The only time you can take a vector \(a\), cross it with a different vector \(b\), and get back the original vector \(a\), is when \(a=0\). But that doesn’t count, since the identity element needs to work for every element in \(G\), not just for zero.
-
-
Inverse
Suppose that we are constructing a long sequence of elements, \(x_1\), \(x_2\), … \(x_n\), where our operator \(\bullet\) is being applied to pairs repeatedly. We might like to know that for any element \(a\) we add to the sequence, there is a corresponding element \(a^{-1}\) that will “undo” the effect of having added \(a\). Such an element is called an inverse element.
The inverse property states that every element in \(G\) has an inverse. That is, for every element \(a \in G\), there exists an element \(a^{-1} \in G\) such that \(a \bullet a^{-1} = a^{-1} \bullet a = e\), where \(e\) is the identity element\(^\dagger\).
-
Example:
The set of integers under addition satisfies the inverse property, since for any \(a \in G\) there exists an \(a^{-1}\), namely \(-a\), such that \(a \bullet a^{-1} = a^{-1} \bullet a = e\), where \(e = 0\). It’s important to remember that we’ve specified \(\bullet\) as meaning addition, so really we’re saying \(a + (-a) = (-a) + a = 0\), for any integer \(a\).
-
Non-example:
The set of integers under multiplication does not satisfy the inverse property, since (for example) 2 cannot be multiplied by any integer to obtain the identity element 1.
\(^\dagger\) Technically, the identity element is not required to define inverses, but this definition will suffice for our purposes.
-
So to recap, a group is any \((G, \bullet)\) which satisfies all four of these properties.
- Closure: For all \(a, b \in G\), we have \(a \bullet b \in G\).
- Associativity: For all \(a, b, c \in G\), we have \((a \bullet b) \bullet c = a \bullet (b \bullet c)\).
- Identity: There exists an element \(e \in G\) such that, for every element \(a \in G\), we have \(a \bullet e = e \bullet a = a\).
- Inverse: For each \(a \in G\) there exists an element \(a^{-1} \in G\), such that \(a \bullet a^{-1} = a^{-1} \bullet a = e\).
Example: The set of integers under addition is a group. The sum of two integers is an integer (closure); order of operations does not matter for addition (associativity); there is an element, 0, which can be added to any other integer without changing it (identity); and above, we saw that the inverse property is also satisfied.
Non-examples: All of the non-examples above are also non-examples of groups, since groups must satisfy all four properties.
Other group-like structures
A group with the additional constraint that its binary operator is commutative (meaning \(a \bullet b = b \bullet a\) for any \(a\) and \(b\)) is called an abelian group.
There are also structures for which some of the above properties hold, but not necessarily all of them. For example, a monoid does not necessarily satisfy the inverse property. See the table below for more examples.
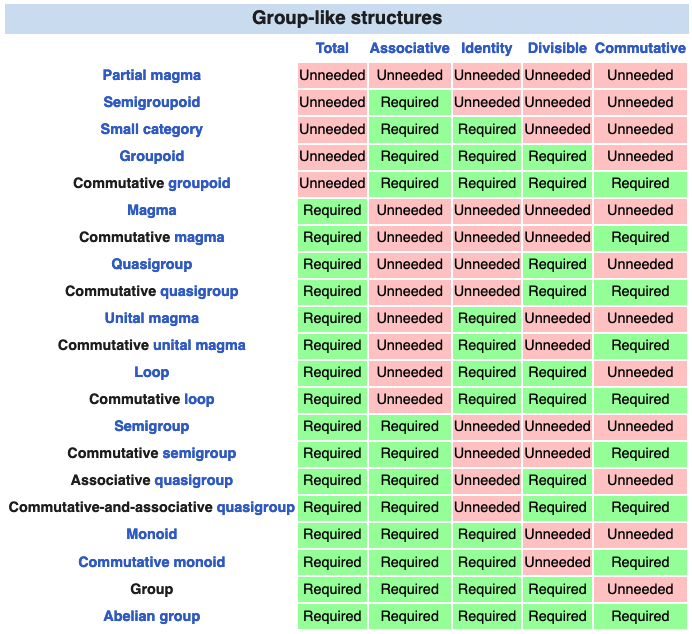 Source: Wikipedia
Source: Wikipedia
So what can you do with groups?
The defining characteristic of abstract algebra is that it’s abstract. About as abstract as math can get. Groups are an abstraction in the same way that sets are an abstraction.
The utility of sets is that you can prove things about them and define operations on them and reason about them without having to repeat yourself every time you encounter another example of a set. All the theory and definitions and reasoning comes along for the ride; you just need to mention that your new example is a set, and you’re good to go.
It’s the same with groups, as well as with the other structures of abstract algebra (rings, fields, vector spaces, etc.).
Since groups are so general, their applications span an incredibly wide range of disciplines, including number theory, coding theory, cryptography, physics, chemistry, algorithm design, graphics, and computer vision.
The Deepmind paper I linked to at the beginning uses groups to define a mathematical foundation for disentangled representation learning. That’s the application we’re particularly interested in understanding here.
But before we dive into what group theory can tell us about disentangled representations, we first need to understand some more pieces.
Subgroups
Definition
If a subset \(H\) of a group \(G\) is itself a group under the operation \(\bullet\) of \(G\), we say that \(H\) is a subgroup of \(G\).
Testing for valid subgroups
Normally, to verify that \((G, \bullet)\) is a group, we need to check that the four group properties hold. But if we know that \(H \subseteq G\), there are alternative ways to check whether \(H\) is a group that are sometimes more convenient.
- If \(H\) is a nonempty subset of \(G\), and \(ab^{-1}\) is in \(H\) whenever \(a\) and \(b\) are in \(H\), then \(H\) is a subgroup of \(G\).
- Proof: \(\bullet\) is already associative. Let \(a=x, b=x\). Then \(xx^{-1} = e \in H\) (identity). Let \(a=e, b=x\). Then \(ex^{-1} = x^{-1} \in H\) (inverse). Consider any \(x,y\in H\). Let \(a=x, b=y^{-1}\). Then \(x(y^{-1})^{-1} = xy \in H\) (closure).
- Using this test to show that \(H\) is a subgroup of \(G\) requires you to (1) identify the property \(P\) that distinguishes the elements of \(H\), (2) prove that \(e\) has the property \(P\), (3) assume that two elements \(a\) and \(b\) have the property \(P\), and (4) use the assumption that \(a\) and \(b\) have property \(P\) to show that \(ab^{-1}\) has property \(P\).
- If \(H\) is a nonempty subset of \(G\), and \(ab\) is in \(H\) whenever \(a\) and \(b\) are in \(H\) (closure under \(\bullet\)), and \(a^{-1}\) is in \(H\) whenever \(a\) is in \(H\) (closure under inverses), then \(H\) is a subgroup of \(G\).
- Proof: \(H\) is nonempty, \(\bullet\) is already associative, \(H\) is closed, and every element in \(H\) has an inverse in \(H\). Let \(a\) belong to \(H\). Then \(a^{-1}\) and \(aa^{-1} = e\) are in \(H\) (identity).
- We can use this test to show \(H\) is a subgroup using the same procedure as for test 1, except here we use the assumption that \(a\) and \(b\) have property \(P\) to prove that \(ab\) and \(a^{-1}\) have property \(P\).
- If \(H\) is a nonempty, finite subset of \(G\), and \(H\) is closed under \(\bullet\), then \(H\) is a subgroup of \(G\).
- Proof: We just need to show that \(H\) is closed under inverses and then invoke test 2. There are two possible cases. If \(a=e\) then \(a^{-1} = a \in H\), and we’re done. If \(a \neq e\), consider the sequence \(a, a^2, ...\). By closure, all of these elements are in \(H\). Since \(H\) is finite, not all of these elements are distinct. Say \(a^i = a^j\) and \(i>j\). Then \(a^{i-j} = e\); and since \(a \neq e\), \(i - j > 1\). Thus \(aa^{i-j-1} = a^{i-j} = e\), and therefore \(a^{i-j-1} = a^{-1}\). Since \(i-j > 1\), we have \(i-j-1 \ge 1\), which implies \(a^{i-j-1}\) is in the sequence, and thus \(a^{-1} \in H\).
Generating subgroups
The smallest subgroup of \(G\) containing a particular element \(a\), is the cyclic subgroup generated by \(a\), which we denote \(\langle a \rangle\). This is shorthand for writing \(\{ a^n\ \vert\ n \in Z\}\).
Repeatedly applying the operator to the powers of \(a\) produces all the elements of \(G\) that are generated by \(a\). For finite groups, it’s easy to see that this is a subgroup, because thanks to associativity, we’ve considered all the possible ways of combining the powers of \(a\) using \(\bullet\), and we’ve included all of them in \(\langle a \rangle\). Alternatively, we can observe that \(a \in \langle a \rangle\), hence \(\langle a \rangle\) is non-empty, and then we can use test 1 above.
In the case where \(\langle a \rangle = G\), we say that \(G\) is cyclic, and that \(a\) is a generator of \(G\).
We can extend this concept from a single element to a set \(S\) of elements from \(G\), and define \(\langle S \rangle\) as the smallest subgroup of \(G\) containing all the elements of \(S\). If \(\langle S \rangle = G\), then we say \(S\) generates \(G\).
Center of a group
Notice that \(\langle a \rangle\) is always Abelian, since by associativity, \(a^n \bullet a^m = a^{n+m} = a^m \bullet a^n\) for any \(a \in G\) and \(n, m \in Z\). This means the elements of \(\langle a \rangle\) commute with each other. However, unless \(\langle a \rangle\) generates \(G\), the elements of \(\langle a \rangle\) may not commute with the other elements of \(G\).
If we want to know the largest subgroup of \(G\) whose elements commute with all the elements of \(G\), we are talking about the center of a group. The center \(Z(G)\) of a group \(G\) is the set of elements in \(G\) that commute with every element of \(G\). More formally, \(Z(G) = \{ a \in G\ \vert\ ax = xa\ \forall\ x \in G \}\). The center of a group \(G\) is always a subgroup of \(G\), and the proof is relatively straightforward if we use subgroup test 2.
A group is Abelian if and only if \(Z(G) = G\), and centerless if Z(G) contains only the identity. The center of a group always includes at least the identity element, since \(eg = g = ge\) for all \(g \in G\), by definition.
We can also talk about the elements of a group \(G\) which commute with a particular element \(a \in G\). These elements are called the centralizer of \(a\) in \(G\), denoted \(C(a)\). Formally, \(C(a) = \{ g \in G\ \vert\ ga = ag \}\). For each \(a \in G\), the centralizer of \(a\) is a subgroup of \(G\), which we can again prove using subgroup test 2.
Example
Let’s take a look at the group \(U(7)\), the set of integers \(\{ 1, 2, ..., 6 \}\) under multiplication modulo 7.
-
\(U(7)\) has the following multiplication table, or Cayley Table:
1 2 3 4 5 6 1 1 2 3 4 5 6 2 2 4 6 1 3 5 3 3 6 2 5 1 4 4 4 1 5 2 6 3 5 5 3 1 6 4 2 6 6 5 4 3 2 1 -
Since the Cayley table is symmetric, \(U(7)\) is commutative; it is an Abelian group.
-
The orders of the elements are: \(\vert 1\vert = 1\); \(\vert 2\vert = 3\); \(\vert 3\vert = 6\); \(\vert 4\vert = 3\); \(\vert 5\vert = 6\); \(\vert 6\vert = 2\).
- The cyclic subgroups generated by the elements of \(U(7)\) are:
- \(\langle 1 \rangle = \{ 1 \}\)
- \(\langle 2 \rangle = \langle 4 \rangle = \{ 1, 2, 4 \}\)
- \(\langle 3 \rangle = \langle 5 \rangle = \{ 1, 2, 3, 4, 5, 6 \} = U(7)\)
- \(\langle 6 \rangle = \{ 1, 6 \}\)
-
Since \(\langle 3 \rangle = \langle 5 \rangle = U(7)\), \(3\) and \(5\) are generators of \(U(7)\).
-
The subgroup generated by \(S = \{1, 2, 6\}\) is \(\{1, 2, 4, 6\}\).
- The center of \(U(7)\) is \(U(7)\) itself, since the group is Abelian. The center contains the elements for which the corresponding row and column of the Cayley table are transposes of each other.
Permutation Groups
Definition
A permutation of a set \(A\) is a function from \(A\) to \(A\) that is both one-to-one and onto (i.e. it’s a bijection). A permutation group of a set \(A\) is a set of permutations of \(A\) that forms a group under function composition.
We will focus on permutation groups for finite sets. We can define a permutation \(\alpha\) of the set \(\{1, 2, 3, 4, 5, 6\}\) by specifying \(\alpha(1) = 2\); \(\alpha(2) = 1\); \(\alpha(3) = 4\); \(\alpha(4) = 6\); \(\alpha(5) = 5\); \(\alpha(6) = 3\).
More conveniently, we can write this correspondence as an array:
\[\alpha = \begin{bmatrix} 1 & 2 & 3 & 4 & 5 & 6 \\ 2 & 1 & 4& 6 & 5 & 3 \end{bmatrix}.\]Cycle Notation
Another useful notation for permutation groups is cycle notation. Instead of writing \(\alpha\) in matrix form, we observe that
\[1 \rightarrow 2 \rightarrow 1\] \[3 \rightarrow 4 \rightarrow 6 \rightarrow 3\] \[5 \rightarrow 5\]Thus we can write the permutation as \(\alpha = (1,2)(3,4,6)(5)\), where each bracketed list corresponds to a cycle.
Typically we omit any cycles containing a single element, as they leave that element unchanged. We can also drop the commas if all the elements are single-digit integers. In this format, the same permutation can be expressed more succinctly as \(\alpha = (12)(346)\). Any permutation must have at least one cycle in this notation, so we usually just write the identity as a single cycle of one element, e.g. \(e=(1)\) or \(e=(5)\).
Symmetric groups
The symmetric group of a set \(A\), written \(S_A\), is the set of all permutations of the set \(A\), and it has order \(\vert A\vert!\). When \(A\) is the set \(\{1, 2, ..., n\}\), \(S_A\) is also called the symmetric group of degree \(n\), and it has order \(n!\).
Some useful facts about permutations
- Any permutation of a finite set can be written as a cycle or a product of disjoint cycles.
- Disjoint cycles commute. For example: \((a, b) (c, d, e) = (c, d, e) (a, b)\).
- Cycles can begin with any element, as long as the order preserves the cycle. For example: \((a, b, c) = (b, c, a) = (c, a, b) \neq (c, b, a)\).
- The composition \(\alpha \circ \beta\) of two permutations \(\alpha\) and \(\beta\) can be written in cycle notation by putting \(\alpha\)’s cycles to the left of \(\beta\)’s cycles. For example, if \(\alpha = (1234)\), and \(\beta = (143)\), then \(\alpha\beta = (1234)(143)\), which we can rewrite as \(\alpha\beta = (1)(23)(4) = (23)\). <!– 5. The order of a permutation of a finite set is the least common multiple of the lengths of its disjoint cycles.
- Every permutation in \(S_n\), for \(n > 1\), can be written as a product of 2-cycles.
- A permutation \(\alpha\) can be expressed as a product of an even number of 2-cycles, if and only if every decomposition of \(\alpha\) into a product of 2-cycles also has an even number of 2-cycles. In this case, we call \(\alpha\) an even permutation. Otherwise it is an odd permutation.
- The set of even permutations in \(S_n\) forms a subgroup of \(S_n\). This subgroup is called the alternating group of degree \(n\), and is denoted by \(A_n\).
- For \(n > 1\), \(A_n\) has order \(n!/2\). As such, there are exactly as many even permutations as odd permutations. –>
Homomorphisms and Isomorphisms
Sometimes we want to know if two groups are functionally the same as each other. This occurs when operations in one group, \(G\), are equivalent to operations in another group, \(H\), and there a mapping between elements of the two groups.
This is exactly the sort of correspondence that allows us to compute the log of a product of two numbers by instead computing the sum of their logs. The computations are functionally the same, and we will get the same result either way.
Homomorphism
A homomorphism \(\phi\) is a mapping from one group to another that preserves the group operation.
That is, if \((G, \bullet)\) and \((H, \star)\) are groups, then a homomorphism is a map \(\phi: G \rightarrow H\) such that:
\[\phi(x \bullet y) = \phi(x) \star \phi(y)\quad \text{for all } x, y \in G\text{.}\]Frequently, we may drop the operators and simply write \(\phi(xy) = \phi(x)\phi(y)\), but it’s important to remember that the product on the left is computed in \(G\) and the product on the right is computed in \(H\). The two groups need not have the same binary operator, just as they need not have the same elements.
Isomorphism
An isomorphism is an invertible mapping between two groups that preserves the group operation.
The map \(\phi: G \rightarrow H\) is called an isomorphism, and \(G\) and \(H\) are isomorphic (written \(G \approx H\)), if:
- \(\phi\) is a homomorphism, (i.e. \(\phi(xy) = \phi(x)\phi(y)\)), and
- \(\phi\) is a bijection.
Intuitively, homomorphisms and isomorphisms are maps from one group to another that preserve the group structure. In the case of isomorphisms, the groups have exactly the same structure, and the mapping \(\phi\) is invertible. For homomorphisms, the mapping might be merely one-way.
If \(\phi\) is a homomorphism from group \(G\) to group \(H\), then there may be multiple elements of \(G\) which map to the identity \(e_H\) of \(H\). We define the kernel of a homomorphism \(\phi\) as the set of all such elements:
\[\text{Ker }\phi = \{x \in G\ \vert\ \phi(x) = e_H \}\text{.}\]If \(\phi\) is an isomorphism from group \(G\) onto group \(H\), then \(\phi(e_G) = e_H\), and \(\text{Ker }\phi = e_G\).
For homomorphisms, any property which \(G\) has, which depends only on the group structure of \(G\) (commutativity, order, and/or cyclicality of the group; subgroups; etc.) also holds in \(H\). For isomorphisms, the converse is also true.
Proving homomorphisms and isomorphisms
There are two steps involved in proving that a group \(G\) is isomorphic to a group \(H\).
- Mapping: Define a candidate for the homomorphism; that is, define a function \(\phi\) from \(G\) to \(H\).
-
Operation-preserving: Prove that \(\phi\) is operation-preserving; that is, show that \(\phi(ab) = \phi(a)\phi(b)\) for all \(a, b \in G\).
Intuitively, this step requires that we are able to obtain the same result by combining two elements and then mapping, or by mapping two elements separately and then combining them.
To prove an isomorphism, there are two additional steps to show that the mapping is a bijection:
- 1-1: Prove that \(\phi\) is one-to-one; that is, assume that \(\phi(a) = \phi(b)\) and prove that \(a = b\).
- Onto: Prove that \(\phi\) is onto; that is, for any element \(h \in H\), find an element \(g \in G\) such that \(\phi(g) = h\).
Examples
-
The mappings \(\phi_1(x) = x^2\) and \(\phi_2(x) = \vert x \vert\) are both homomorphisms mapping \(\mathrm{R}^*\), the nonzero real numbers under multiplication, to itself, since:
- \(\phi_1(xy) = (xy)^2 = x^2 y^2 = \phi_1(x) \phi_1(y)\), and
- \(\phi_2(xy) = \vert xy\vert = \vert x\vert \vert y\vert = \phi_2(x) \phi_2(y)\)
for all \(x,y \in \mathrm{R}^*\). Both mappings have the same kernel: \(\text{Ker } \phi_1 = \text{Ker } \phi_2 = \{-1, 1\}\).
-
Let \(G\) be the real numbers under addition, and let \(H\) be the positive real numbers under multiplication. Then \(G\) and \(H\) are isomorphic under the mapping \(\phi(x) = 2^x\).
The mapping is clearly from \(G\) to \(H\). It is one-to-one; if \(2^x = 2^y\), then \(\log_2 2^x = \log_2 2^y\), and therefore \(x = y\). It is onto; for any \(y\), we need an \(x\) such that \(2^x = y\), which we can simply solve to obtain \(x = \log_2 y\). Finally, it is operation-preserving, since:
\[\phi(x + y) = 2^{x+y} = 2^x \bullet 2^y = \phi(x) \phi(y) \quad\text{for all } x, y \in G\text{.}\] -
In linear algebra, every linear transformation from a vector space \(V\) to a vector space \(W\) is a group homomorphism from \(V\) to \(W\), and the null-space is the same as the kernel. If the transformation is invertible, it is a group isomorphism.
-
Any finite cyclic group \(\langle a \rangle\) of order \(n\) is isomorphic to \(Z_n\) under the mapping \(a^k \rightarrow k \mod n\).
-
Any infinite cyclic group is isomorphic to \(Z\) under the mapping \(a^k \rightarrow k\), for any generator \(a\) of the cyclic group.
Non-examples
-
The mapping from \(\mathrm{R}\) under addition to itself given by \(\phi(x) = x^3\) is neither a homomorphism nor an isomorphism. Even though \(\phi\) is one-to-one and onto, it is not operation-preserving: there exist some \(x\) and \(y\) such that \((x+y)^3 \neq x^3 + y^3\); for example, with \(x = y = 1\), we have \((1+1)^3 \neq 1^3 + 1^3\).
-
There is no isomorphism from \(\mathrm{Q}\), the group of rational numbers under addition, to \(\mathrm{Q}^*\), the group of non-zero rational numbers under multiplication. If \(\phi\) were such a mapping, there would exist a rational number \(a\) such that \(\phi(a) = -1\). As a consequence,
\[-1 = \phi(a) = \phi\left(\frac{1}{2}a + \frac{1}{2}a\right) = \phi\left(\frac{1}{2}a\right) \phi\left(\frac{1}{2}a\right) = \left[\phi\left(\frac{1}{2}a\right)\right]^2;\]however, no rational number can be squared to obtain \(-1\).
Cayley’s Theorem
Theorem: Every group is isomorphic to a group of permutations.
Proof: Let \(G\) be any group. We need to find a group \(\overline{G}\) of permutations that is isomorphic to \(G\).
All we have is \(G\), so we need to use it to construct \(\overline{G}\) such that the two are isomorphic. We do this by defining a function \(T_g\) from \(G\) to \(G\). For any \(g \in G\), \(T_g(x): G \rightarrow G\) is defined as follows:
\[T_g(x) = gx \quad \text{for all } x \in G.\]This is a fancy way of saying \(T_g(x)\) just multiplies \(x\) on the left by \(g\).
We can see that \(T_g\) is a permutation by considering row \(g\) of the Cayley table for \(G\). Each \(x \in G\) gets mapped to an element \(y = gx\), (and \(gx \in G\), by closure); therefore there are no empty cells in the row. We can show every cell is unique by contradiction. Assume an element \(y\) appears twice in the row, such that \(ga = y = gb\), with \(a \neq b\). Then \(a = g^{-1}y = b\), and hence \(a = b\). But \(a \neq b\) by assumption, therefore every \(y\) must be unique. This means every element of \(G\) appears exactly once in the row, and thus \(T_g\) is a permutation.
Now, let \(\overline{G} = \{T_g\ \vert\ g \in G\}\). Then \(\overline{G}\) is a group under function composition. First, we observe that for any \(g, h \in G\), we have \(T_gT_h(x) =\) \(T_g(T_h(x)) =\) \(T_g(hx) =\) \(g(hx) =\) \((gh)x =\) \(T_{gh}(x)\), so that \(T_gT_h = T_{gh}\) (closure). From this it follows that \(T_e\) is the identity and that \({T_g}^{-1} = T_{g^{-1}}\). Since function composition is associative, \(\overline{G}\) is a group.
Now we can define the isomorphism \(\phi\) between \(G\) and \(\overline{G}\). For every \(g\in G\), define \(\phi(g) = T_g\). It is a mapping from \(G \rightarrow \overline{G}\). It is one-to-one; if \(T_g = T_h\) then \(T_g(e) = T_h(e)\), which means \(ge = he\), and hence \(g = h\). Because of how we constructed \(\overline{G}\), \(\phi\) is onto. We just need to check if the mapping is operation-preserving. Let \(a, b\) be elements of \(G\). Then
\[\phi(ab) = T_{ab} = T_a T_b = \phi(a) \phi(b)\text{.}\]Thus we can see that \(\phi\) is an isomorphism. Therefore, there exists a group \(\overline{G}\), for every group \(G\) such that \(\overline{G}\) is isomorphic to \(G\).
Group Actions
In a similar way to how functions can be said to “act” on their arguments, groups can be said to act on other structures (e.g. sets, groups, vector spaces).
A group action occurs when each element of the group can be thought of as corresponding to a particular transformation of the other structure on which the group is acting.
Let’s start with the simplest type of structure that groups can act on, namely sets.
Groups acting on sets
Let \((G,\star)\) be a group, and let \(A\) be a set. A group action of \(G\) on \(A\) is a map from \(G \times A\) to \(A\) (which we will write as \(g\cdot a\) for all \(g \in G\) and \(a \in A\)), satisfying the following properties:
-
\(g_1 \cdot (g_2 \cdot a) = (g_1 \star g_2)\cdot a, \quad\text{for all } g_1, g_2 \in G, a \in A\); and
This means that we can combine two transformations from \(G\) and then apply the joint transformation to \(A\), or we can apply each individual transformation to \(A\) separately, as long as we do it in the correct order.
-
\(e_G \cdot a = a, \quad\text{for all } a \in A\).
This means that the identity element of \(G\) must correspond to the trivial transformation of \(A\) which maps each element to itself.
When a mapping exists that satisifes these properties, we say that \(G\) is acting on \(A\).
Note that \(\cdot\) represents the group action map, whereas \(\star\) is the binary operation of \(G\). Astonishingly, people will often drop both \(\cdot\) and \(\star\), and expect that the meaning will be obvious from context. But thankfully, the first property above says that whether we mean \(g_1 \cdot (g_2 \cdot a)\) or \((g_1 \star g_2)\cdot a\), we can simply write \(g_1\ g_2\ a\), because the result is the same (like a weird form of associativity). For clarity, we’ll only drop the \(\star\) here.
A consequence of the above definition is that for each fixed \(g \in G\), we get a map \(\sigma_g: A \rightarrow A\), such that \(\sigma_g(a) = g\cdot a\).
This interpretation leads to two important facts:
-
For each fixed \(g \in G\), \(\sigma_g\) is a permutation of \(A\).
Proof: For all \(a\in A\), we have:
\[\begin{align*} (\sigma_g^{-1} \circ \sigma_g)(a) &= \sigma_g^{-1}(\sigma_g(a))\\ &= g^{-1} \cdot (g \cdot a)\\ &= (g^{-1} g) \cdot a \\ &= e_G \cdot a \\ &= a\text{.} \end{align*}\]And by the same logic, \((\sigma_g \circ \sigma_g^{-1})(a) = a\). Therefore \(\sigma_g\) is an invertible map from \(A \rightarrow A\), and as such, it is a permutation.
-
The map from \(G\) to \(S_A\) (the symmetric group of set \(A\)) defined by \(g \mapsto \sigma_g\) is a homomorphism.
Proof: Let \(\phi: G \rightarrow S_A\) be defined as \(\phi(g) = \sigma_g\). We’ve already determined above that \(\sigma_g \in S_A\), so the map is well-defined.
Now let’s check if \(\phi\) is operation-preserving. For all \(a \in A\), we have:
\[\begin{align*} \phi(g_1 g_2)(a) &= \sigma_{g_1 g_2}(a) \\ &= (g_1 g_2) \cdot a \\ &= g_1 \cdot (g_2 \cdot a) \\ &= \sigma_{g_1}(\sigma_{g_2}(a)) \\ &= (\phi(g_1) \circ \phi(g_2))(a) \end{align*}\]Therefore, \(\phi\) is a homomorphism.
In this way, we see that the elements of \(G\) correspond to permutations of set \(A\) in a manner consistent with the group operations in \(G\). We can also start with any homomorphism from \(G\) to \(S_A\) and use it to define a group action of \(G\) on \(A\). There is a bijection between the actions of \(G\) on \(A\) and the homomorphisms of \(G\) into \(S_A\).
The homomorphism \(\phi\) from \(G\) to \(S_A\) defined above is called the permutation representation of the given action.
Examples
-
Let \(G\) be any group and let \(A = G\). Define a map from \(G \times A\) to \(A\) by \(g \cdot a = ga\) for each \(G \in G\) and \(a \in A\), where \(g\cdot a\) refers to the group action map, and \(ga\) is the product of \(g\) and \(a\) in the group \(G\). This defines a group action of \(G\) on itself, where each (fixed) \(g \in G\) permutes the elements of \(G\) by left multiplication:
\[g : a \mapsto ga\quad \text{for all } a \in G\](or, if \(G\) is written additively, we get \(g : a \mapsto g+a\) and call this left translation). This action is called the left regular action of \(G\) on itself. The corresponding homomorphism from \(G\) to \(S_A\) is called the left regular representation of \(G\).
We have already seen this action and its representation in our proof of Cayley’s Theorem above.